
Several widely used NLP algorithms
Images in this blog are borrowed from lecture note of Prof. Bal Krishna Bal.
Not only are there many algorithms for machine learing tasks, but also for natural language processing job. The choice of which algorithm is best for a given problem cannot be made with absolute certainty. After determining our objectives, we should select algorithms. The algorithms listed below range in complexity from simple to complicated.
Approaches to NLP
Heuristics-Based NLP
-
Early attempts to construct rules for the task at hand when designing NLP systems.
-
Need human competence in the relevant domain.
-
Also needs sources like thesauruses and dictionaries, which are often compiled and digitalized over time. lexicon-based sentiment analysis, as an illustration.
-
Greater complexity of knowledge bases. Consider WordNet, a database of words and the semantic connections between them.
-
When developing rule-based systems around a language, lexical resources like the WordNet are highly helpful.
-
Regular expressions, or “regex,” are an excellent tool for analyzing text and creating rule-based systems.
-
Context-free grammar (CFG) is a formal grammar that imitates the structure of natural language.
-
Rules and heuristics are excellent building blocks for initial NLP systems.
-
They typically serve to fill up any holes in the system.
Machine Learning For NLP
-
For a variety of NLP tasks, supervised ML approaches including classification and regression methods are frequently utilized.
-
An example of an NLP classification task would be to group news articles into categories like politics or sports.
-
Regression methods provide a numerical estimate of a stock’s price based on online discussions. Texts are grouped together using techniques for unsupervised clustering.
-
The three typical processes in every machine learning (ML) technique, whether supervised or unsupervised, are: 1) extracting features from the text; 2) using the feature representation to learn a model; and 3) evaluating and improving the model.
Commonly Used Supervised ML Methods in NLP
Naive Bayes
The Bayes theorem is the foundation of the traditional classification technique known as naive Bayes. Based on the set of features for the input data, it determines the likelihood of witnessing a class label using the Bayes theorem. Nave Bayes is frequently used as a starting algorithm for text classification since it is straightforward to learn, quick to train, and quick to utilize. The technique makes the assumption that each feature is independent of all other characteristics.
Support Vector Machine
Another well-known classification algorithm is SVM. It’s objective is to discover a decision boundary that serves as a distinction between several text categories (e.g., politics versus sports). Both linear and nonlinear decision boundaries are possible (e.g., a circle). To distinguish data points from several classes, an SVM can be trained to learn both a linear and a nonlinear decision boundary. In order to maximize the distance between points across classes, an SVM learns an ideal decision boundary. The ability of SVMs to withstand fluctuations and data noise is one of their greatest assets. The time required for training and the inability to scale when there is a lot of data present are two big weaknesses.
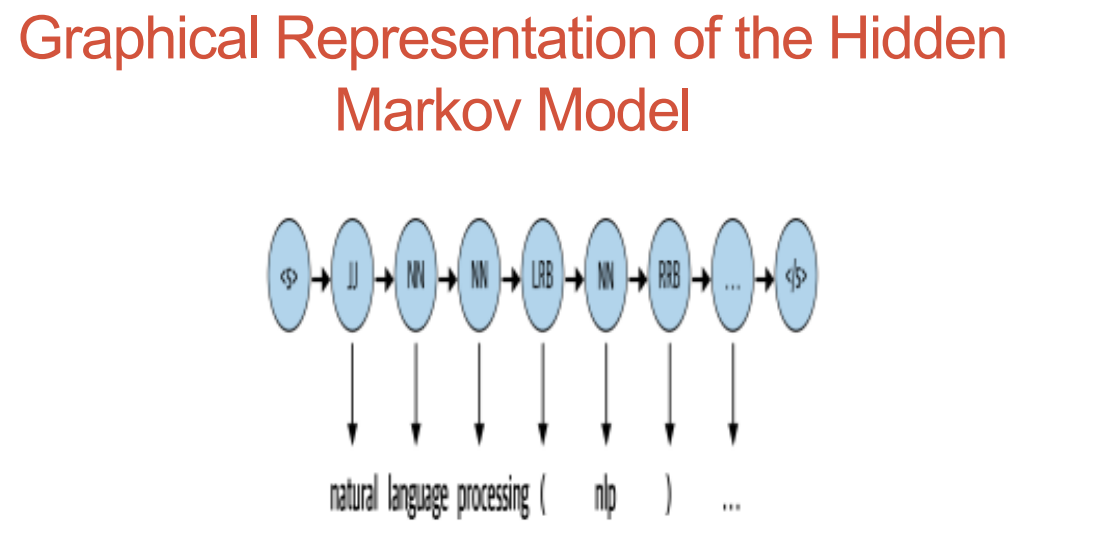
Hidden Markov Model
The Hidden Markov Model (HMM)is a statistical model, makes the assumption that the data are produced by an underlying, observable process with hidden states, as a result, the data can only be observed once they have been produced. Then, using this information, an HMM tries to model the hidden states. As an illustration, think about word part-of-speech tags in sentences. The essential premise is that concealed behind the text, a grammar is used to generate the text. The hidden states of speech are categories of words that follow language grammar to establish the sentence structure fundamentally. We only pay attention to the words that fall under the control of these latent states. HMMs also rely on the Markov assumption, which states that each hidden state depends on the one before it (s). Because human language is sequential in nature, the preceding word in a phrase affects the following word. HMMs with these two suppositions are an effective modeling tool.
Conditional Random Fields
Yet another sequential data method. Conceptually, a CRF just assigns each element in the sequence to a classification task.A CRF typically tags words one by one by assigning them to one of the POS tags that represent the various parts of speech.Since it incorporates the sequential input and the tag context,Taking this into account, it expresses itself more fully than normal. classification techniques and consistently outperforms them. CRFs perform better than HMMs in jobs like POS tagging, which rely regarding the orderly character of language.
Deep Learning for NLP
Recurrent neural networks (RNNs) are particularly crafted with sequential learning and processing in mind. RNNs have neural units that are able to recall the information they have already processed. As the RNN reads the next word in the input, the data is updated and stored in this temporal memory with each time step. RNNs are capable of handling a wide range of NLP tasks, including text categorization, named entity identification, machine translation, etc. RNNs can also be used to create text with the intention of reading previous text and predicting the following word or character.
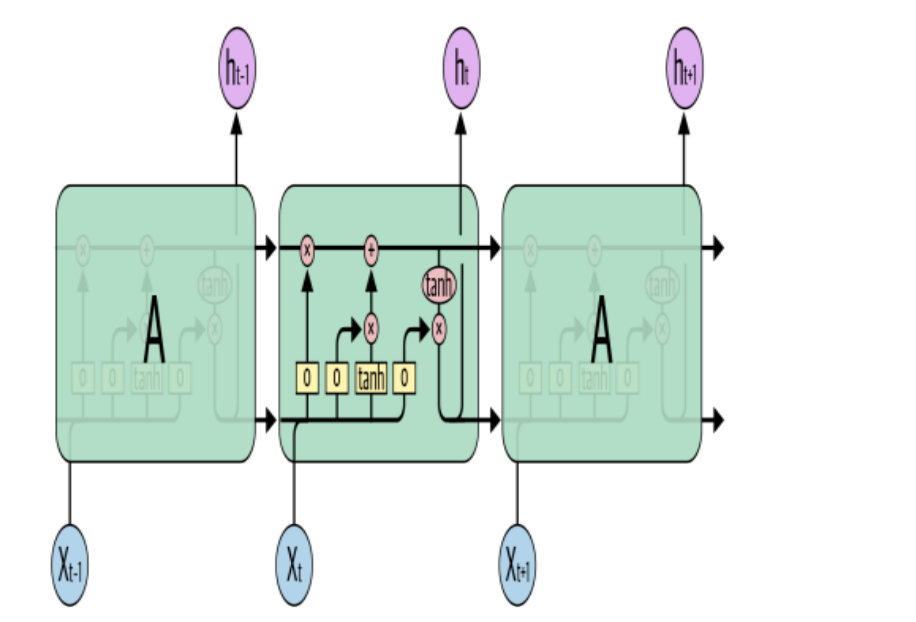
Long Short-Term Memory(LSTM)
RNNs experience forgetful memory, which causes them to struggle with lengthy texts and be unable to remember extended contexts. By discarding the irrelevant information and just keeping in mind the portion of the context required to complete the task at hand, LSTMs, a type of RNN, get around this issue. Another RNN variant that is mostly utilized for language production is the gated recurrent unit (GRU).
Convolutional Neural Networks
CNN are widely used and very popular in computer vision applications including video recognition and picture classification, among others. CNNs have also been successful in NLP, particularly with problems involving text classification. Every word in a sentence has a corresponding word vector that can be used to replace it, and all of the word vectors are the same size (d). Since n is the number of words in the sentence and d is the size of the word vectors, they can be stacked on top of one another to create a matrix or 2D array of dimension n x d. This matrix can now be modeled by a CNN and treated as a picture. The capacity of CNNs to use a context window to view a set of words collectively is its main benefit.
Transformers
Transformers are the most recent addition to the NLP category of deep learning models. Over the past two years, transformer models have surpassed the state-of-the-art in nearly all significant NLP tasks. They don’t model the textual context sequentially, though. When presented with a word in the input, it prefers to consider every word in its immediate vicinity (a process known as self-attention) and represent each word in light of its contexts. Transformers have a better representation capacity than other deep networks and are therefore frequently utilized in NLP applications since they can model such context. Large transformers have recently been employed for transfer learning with more compact downstream jobs.
The goal behind transformers is to train a very big transformer model in an unsupervised setting (referred to as pre-training) to predict a portion of the phrase given the rest of the material so that it can encode the high-level intricacies of the language.
language is present,
-
More than 40 GB of textual data were used to train these models. Entire internet.
-
The BERT (Bidirectional Encoder) is a prime illustration of a big transformer. Symbols from the movie Transformers)
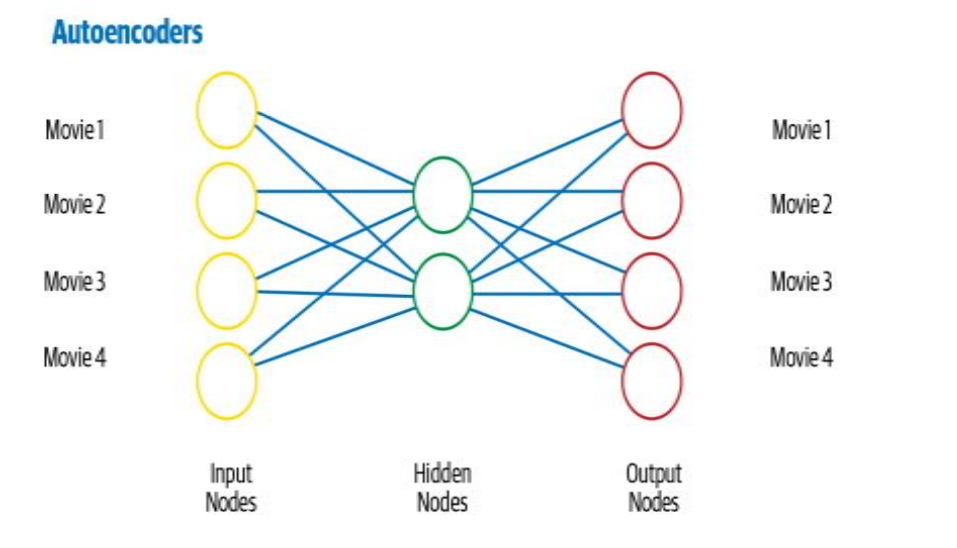
Autoencoders
A separate class of network known as an autoencoder is employed mostly for learning compressed vector representations of input. Following training, we gather the vector representation, which serves as a dense vector encoding of the input text. The creation of feature representations required for any subsequent activities is often accomplished using autoencoders. In the autoencoder, the hidden layer provides a compressed representation of the input data, encapsulating its essence, and the top layer (the decoder), which is responsible for reconstructing the input representation, does so using the compressed representation.Different autoencoders address the unique characteristics of sequential data, like text, including LSTM autoencoders.
Why Deep Learning is Still not a Go-to Solution for NLP
- Overfitting on small datasets
DL models overfit on limited datasets, which results in a lack of generalization capacity and poor production performance.
- Few-shot learning and synthetic data generation
This is not yet seen for NLP unlike in disciplines like Computer Vision.
- Domain adaptation
The models trained in one domain cannot actually be extended to other domains because DL models are not particularly strong at generalization.
- Interpretable models
For DL models, interpretability is challenging because, for the most part, they operate in a black box.
- Common sense and world knowledge
Current DL models are still unable to handle logical reasoning and common sense understanding.
- Cost
Costly in terms of money and time.
- On-device deployment
The need to deploy the model on embedded device and resource limitations of the device.


Comments