
NLP Pipeline
Images in this blog are borrowed from lecture note of Prof. Bal Krishna Bal.
The end-to-end structure that orchestrates the flow of data into and output from a NLP model is known as a natural learning pipeline (or set of multiple models). It covers the input of the raw data, the features, the outputs, the machine learning model and model parameters, and the outputs of the predictions. NLp pipeline is also define as the step by step process of text.
Key stages:
-
Data acquisition
-
Text cleaning
-
Pre-processing
-
Feature engineering
-
Modeling
-
Evaluation
-
Deployment
-
Monitoring and model updating
Data Acquisition
The process of sampling signals that gauge actual physical circumstances and transforming the resulting samples into digital numeric values that a computer can manipulate is known as data acquisition. In simple meaning data acquisition is the process of collecting, prepare data in the computer readable format. There are variety of data are in various sources. So, at first we should scrap data and pull them in the machine readable format and this process is known as data acquisition.
Data Enhancement
-
Synonym substitution (add texts with words replaced by their synonyms)
-
Back translation (adding to the source texts that are the target translation’s back translation).
-
TF-IDF based word substitution (use TF-IDF results to replace words in the text)
-
The Bigram flip (add texts with flipped order of bigrams) / Swapping out entities (add texts with replaced entities)
-
Making data noisier (add words that have similar spellings)
Advanced strategies:
-
Snorkel (which uses heuristics to generate synthetic data by altering current data and generating new data samples) (builds massive training data sets automatically without manual labeling). NLPAug and Simple Data Augmentation (libraries for creating synthetic samples for NLP)
-
Active Education (algorithm interactively queries a data point and gets its label)
Text Extraction and Cleanup
-
Process of separating the raw text from the other non-textual information, such as markup, metadata, etc., and converting the text to the necessary encoding format from the input data is called text extraction.
-
HTML Parsing and Cleanup:
- Writing a HTML parser
- Using existing libraries – Beautiful Soup, Scrapy
-
Unicode Normalization
-
Text encoding and conversion to machine-readable forms (such as emojis).
-
There are various encoding schemes, and the default encoding for various operating systems may vary.
-
Spelling correction
-
System-specific error correction(outputs of ASR or OCR that requires correction or post-editing)
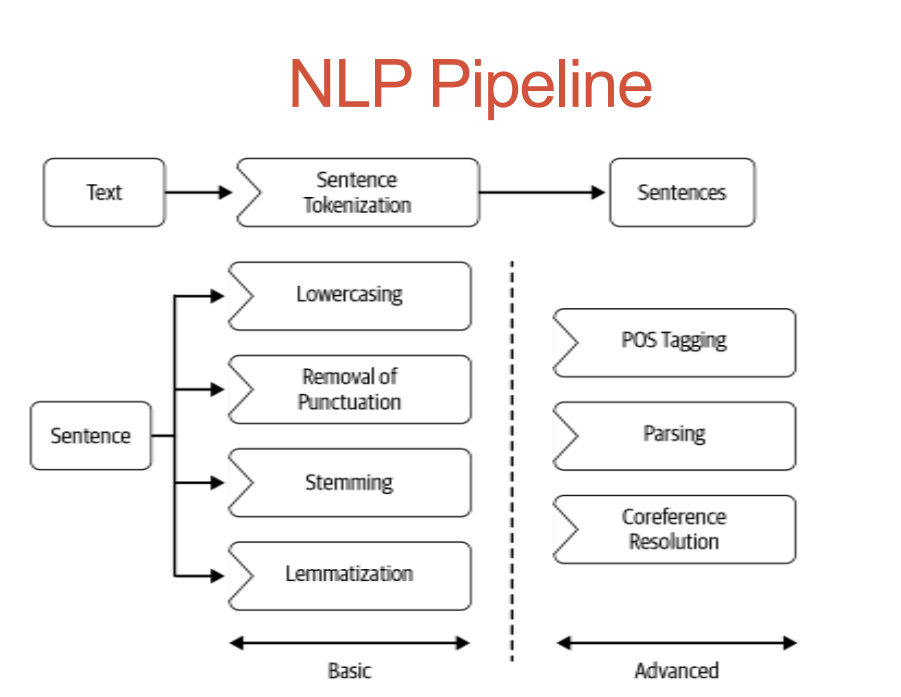
Pre-processing
- Preliminaries
Sentence segmentation and word tokenization: Process of splitting paragraph into sentence level or sentence into word level is called tokenization or word segmentation.
- Frequent steps
- Stop word removal, stemming and lemmatization, removing digits/punctuation, lowercasing, etc.
- Other steps
- Normalization, language detection, code mixing, transliteration, etc.
- Advanced processing
- POS tagging, parsing, coreference resolution, etc.
Stemming and Lemmatization
Stemming: Technique of stripping a word of its suffixes and reducing it to a basic form so that all of the word’s variations can be represented by the same form.
Lemmatization: The process of mapping every word form to its root word, or lemma, is known as lemmatization.
Stemming and Lemmatization

Other Preprocessing Steps
- Text normalization
- Lowercase to uppercase conversion
- Text to digit conversion
- Abbreviation expansion
- Language recognition
- the usage of libraries like Polyglot
- Transliteration and code mixing
- Advanced pre-processing
Feature Engineering/Extraction
- A group of techniques that convert textual traits into a numeric vector that machine learning algorithms can comprehend.
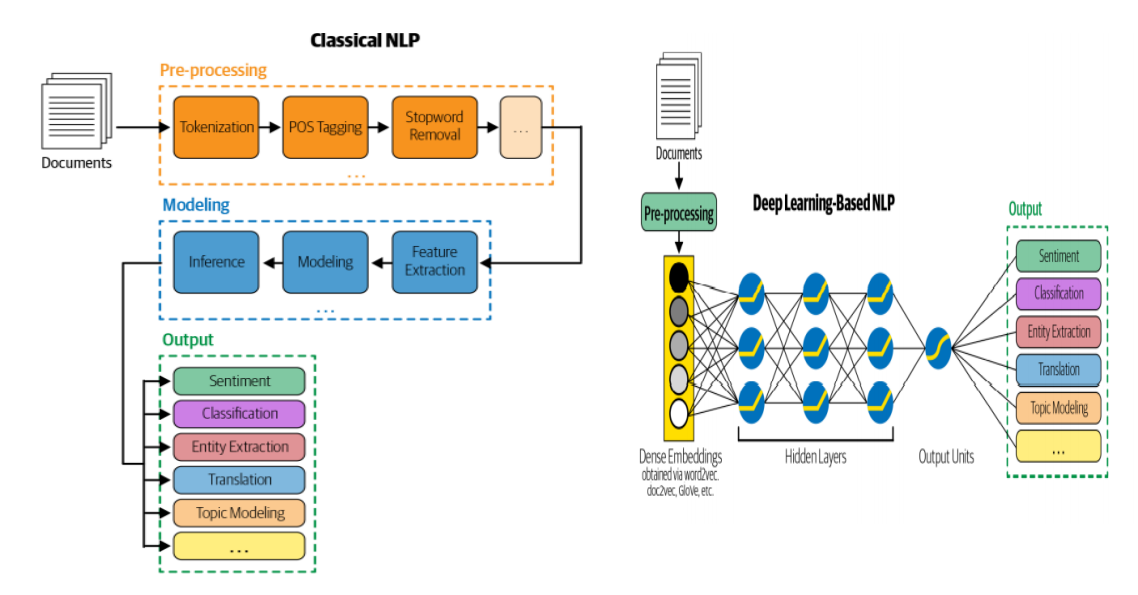
Classical NLP/ML Pipeline
-
The raw data is transformed into a machine-readable format during the feature engineering process. In the traditional ML pipeline, the transformation functions are often handmade and tailored to the task at hand.
-
The task at hand and subject expertise serve as major sources of inspiration for features.
-
A major benefit of handcrafted features is that they maintain the model’s interpretability, making it easy to quantify the contribution of each feature to the model’s prediction.
DL Pipeline
- The primary flaw in traditional ML models is feature engineering.
- Handcrafted feature engineering causes a bottleneck in the model development cycle and its performance.
-
After pre-processing, the raw data is delivered straight to a model in the DL pipeline. Although the model is capable of “learning” features from the data, the model lacks interpretability because all these features are taught via model parameters.
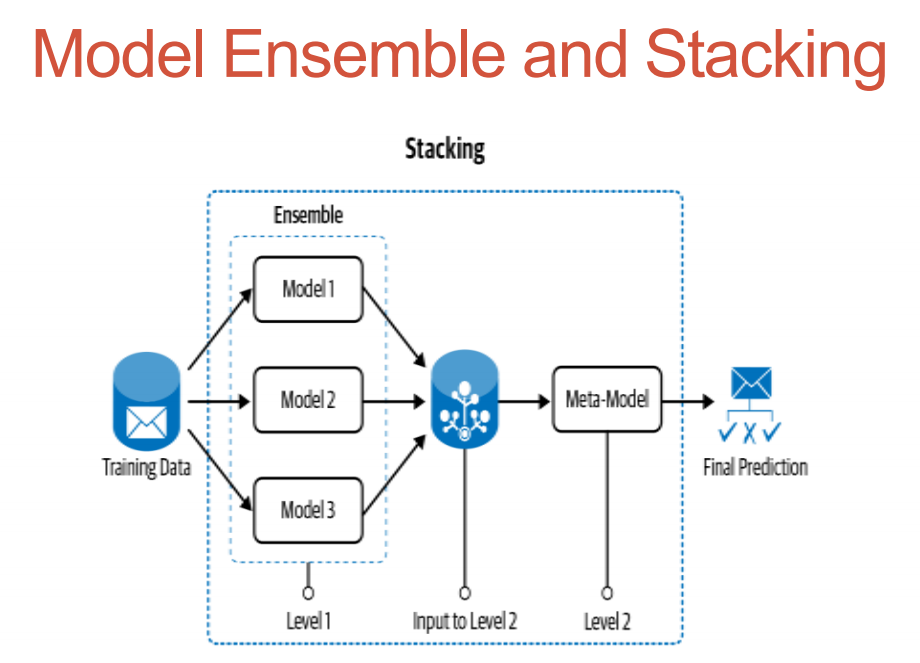
Modeling
- Start with simple heuristics
- Building your model Pre-process your input to the ML model (use available NLP techniques before feeding your input to the ML model) by creating a feature from the heuristic.
- Model construction
- ensemble and stacking
- Improved feature engineering
- Transfer learning
- Reapplication of heuristics
Evaluation
- Measuring the quality of the model we’ve developed is an important stage in the NLP process.
- A measure of how well the model performs on unobserved data.
- Using the proper evaluation metric and adhering to the proper evaluation method are essential for success.
- There are two different types of evaluation 1.intrinsic 2. extrinsic. The former focuses on measuring the system’s performance using precision and recall, while the latter evaluates performance in relation to the goal.
Post modeling phases
- Once our model has been tried and tested, we move on to the post modeling phase,
1) deploying
2) monitoring
3) model updating


Comments