
News Classification with Simple Neural Network is one of the application of Deep Learning. And here in this part of the blog, I am going to perform a Nepali News Classification. Before jumping into the main part, I would love to share some of my previous contents based upon which this blog has been written.
- How I collected news data?
- EDA in Nepali News Data
- Nepali News Classification with Logistic Regression
- Nepali News Classification with Naive Bayes
Above blogs are written and performed by me on sequential order too. The part in this blog until the pre-processing of text is same throughout the other classification blog too.
Import Necessary Module
Lets import necessary modules that we need to data preprocession before modelling.
-
os: The OS module in Python provides functions for interacting with the operating system and files. -
pandas: Working with DataFrame and data analysis. -
numpy: For numerical operaiton and array stuffs. -
matplotlib: For visualization. -
matplotlib.front manager: A module for finding, managing, and using fonts across platforms -
matplotlib.front manager: A module for finding, managing, and using fonts across platforms -
matplotlib.front manager: A module for finding, managing, and using fonts across -
warnings: Warnings are provided to warn the developer of circumstances that aren’t always exceptions.
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
from matplotlib.font_manager import FontProperties
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
import pprint
plt.style.use("seaborn-whitegrid")
Data Load
The data is currently in my drive which is available publicly. And I run the scraping code frequently to get more data so the number of rows could be different later.
I used data that I had gathered over the course of a month or two by scraping news from several news portals. This daily news was amalgamated, and I created a final consolidated csv file that I used here. That file has 5348 rows and 9 columns. In columns I kept different news fields like business, sports, news, entertainment etc as attributes.
df = pd.read_csv("/content/drive/MyDrive/News Scraping/combined_csv.csv")
df.shape
(5838, 9)
df.Category.value_counts()
business 1550
news 1228
entertainment 1092
technology 441
prabhas-news 441
sports 420
world 331
national 120
international 120
province 95
Name: Category, dtype: int64
From above, we can see that most news belongs to the business category and the entertainment category, similarly to the news category. While doing classification problems, the first requirement is that we should have an equal number of data points in all classes. If not, there is the problem of class imbalance, which arises because our model will classify data in the majority of classes and ignore the rest of the classes. Hence, we should be more concerned with how to achieve class balance.
One way to make sure classes are balanced here is to combine two or more classes into single classes. While doing that task, we combined classes that have similar types of data, like in the above categories of news and prabhas-news, international and world, and so on.
# # business, entertainment
# df.query('Category in ("business", "entertainment")')
# # business, entertainment, technology, sports, world + international
Open the stopwords.txt file.
Stop words are a collection of terms that are commonly used in any language. Stop words in English include words like “the,” “is,” and “and.” Stop words are used in NLP and text mining applications to remove extraneous terms so that computers may focus on the important ones. The following is how I loaded the stop words file. Because stop words play an important role in news classification, we should eliminate them during preprocessing.
Stop words file
stop_file = "/content/drive/MyDrive/News Scraping/News classification/nepali_stopwords.txt"
stop_words = []
with open(stop_file) as fp:
lines = fp.readlines()
stop_words =list( map(lambda x:x.strip(), lines))
#stop_words
Open the Punctuation file.
The code below is for loading a punctuation file. Punctuation is a set of tools used in writing to clearly distinguish sentences, phrases, and clauses so that their intended meaning may be understood. These tools provide no useful information during categorization, thus they should be eliminated before we train our model.
punctuation_file = "/content/drive/MyDrive/News Scraping/News classification/nepali_punctuation (1).txt"
punctuation_words = []
with open(punctuation_file) as fp:
lines = fp.readlines()
punctuation_words =list( map(lambda x:x.strip(), lines))
punctuation_words
[':', '?', '|', '!', '.', ',', '" "', '( )', '—', '-', "?'"]
Pre-processing of text
I’m only going to utilize the titles of all of my blog’s categories. I’ll use content to make a blog post there later, despite the enormous quantity of words in the content columns. In this blog, I’ll show you how to use Naive Bayes in title data to classify news and categorize it by category.
First, I created a method named ‘preprocessing text’ in the provided code that accepts data, stop words, and punctuation words as parameters. I made a list called ‘new cat’ to keep track of the information once I processed it. I also initialized naise, as you can see in the code. Then, within cat data, I use for loop. I isolated the data on cats from the white space, linked them together, and gave them names.
def preprocess_text(cat_data, stop_words, punctuation_words):
new_cat = []
noise = "1,2,3,4,5,6,7,8,9,0,०,१,२,३,४,५,६,७,८,९".split(",")
for row in cat_data:
words = row.strip().split(" ")
nwords = "" # []
for word in words:
if word not in punctuation_words and word not in stop_words:
is_noise = False
for n in noise:
#print(n)
if n in word:
is_noise = True
break
if is_noise == False:
word = word.replace("(","")
word = word.replace(")","")
# nwords.append(word)
if len(word)>1:
nwords+=word+" "
new_cat.append(nwords.strip())
# print(new_cat)
return new_cat
title_clean = preprocess_text(["शिक्षण संस्थामा ज जनस्वास्थ्य 50 मापदण्ड पालना शिक्षा मन्त्रालयको निर्देशन"], stop_words, punctuation_words)
print(title_clean)
['शिक्षण संस्थामा जनस्वास्थ्य मापदण्ड पालना शिक्षा मन्त्रालयको निर्देशन']
Here, we only take title from our data and apply stops words and punctuations.
ndf = df.copy()
cat_title = []
for i, row in ndf.iterrows():
ndf.loc[i, "Title"]= preprocess_text([row.Title], stop_words, punctuation_words)[0]
ndf.head()
| Unnamed: 0 | Title | URL | Date | Author | Author URL | Content | Category | Description | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | प्रधानमन्त्री देउवा, दाहाल नेपाल भारतीय राजदूत... | https://ekantipur.com/news/2022/04/12/16497794... | चैत्र २९, २०७८ | कान्तिपुर संवाददाता | https://ekantipur.com/author/author-14301 | काठमाडौँ — प्रधानमन्त्री शेरबहादुर देउवा, नेकप... | news | प्रधानमन्त्री शेरबहादुर देउवा, नेकपा (माओवादी ... |
| 1 | 1 | गठबन्धनले महानगर उपमहानगरमा प्रमुख-उपप्रमुख के... | https://ekantipur.com/news/2022/04/12/16497772... | चैत्र २९, २०७८ | कान्तिपुर संवाददाता | https://ekantipur.com/author/author-14301 | काठमाडौँ — स्थानीय तहको निर्वाचनका लागि सत्ता ... | news | स्थानीय तहको निर्वाचनका लागि सत्ता गठबन्धन दलह... |
| 2 | 2 | परराष्ट्रमन्त्री खड्कासँग भारतीय राजदूत क्वात्... | https://ekantipur.com/news/2022/04/12/16497754... | चैत्र २९, २०७८ | कान्तिपुर संवाददाता | https://ekantipur.com/author/author-14301 | काठमाडौँ — भारतको विदेश मन्त्रालयमा सचिव पदमा ... | news | भारतको विदेश मन्त्रालयमा सचिव पदमा नियुक्त भएप... |
| 3 | 3 | स्थानीय तहको नेतृत्व बाँडफाँट केन्द्रमा पठाउन ... | https://ekantipur.com/news/2022/04/12/16497720... | चैत्र २९, २०७८ | कान्तिपुर संवाददाता | https://ekantipur.com/author/author-14301 | काठमाडौँ — सत्ता गठबन्धनले स्थानीय तहको नेतृत्... | news | सत्ता गठबन्धनले स्थानीय तहको नेतृत्व बाँडफाँट ... |
| 4 | 4 | प्रधानसेनापति भारतीय सेनाका रथीबीच भेटवार्ता | https://ekantipur.com/news/2022/04/12/16497700... | चैत्र २९, २०७८ | कान्तिपुर संवाददाता | https://ekantipur.com/author/author-14301 | काठमाडौँ — प्रधानसेनापति प्रभुराम शर्मा र भारत... | news | प्रधानसेनापति प्रभुराम शर्मा र भारतीय सेनाका र... |
Importing Necessary Module for simple neural network
Here first we import to_categorical from tensorflow.kers.utlis. It is used to make our label data into one hot encoded form. OHE form is very useful form in the multiclass classification because it gives 1 when current word lies in the current class and and 0 to all other classes.
Lets import
OneHotEncoder: Encode categorical features as a one-hot numeric arrayconfusion_matrix: For classification model perfprmancesequence: The sequential API allows you to create models layer-by-layer for most problems fromTokeniaer: To tokenize the paragraph into sentence level or sentence into word level
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics import confusion_matrix
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout
from tensorflow.keras.utils import to_categorical
data = pd.DataFrame()
data["text"]=ndf.Title
data["label"]=ndf.Category
data["target"] = data["label"].apply(lambda x: "news" if x=="prabhas-news" else "national" if x=="province" else "world" if x=="international" else x)
classes = {c:i for i,c in enumerate(data.target.unique())}
data["target"] = data.target.apply(lambda x: classes[x])
targets = to_categorical(data.target)
vectorizer = CountVectorizer(ngram_range=(1, 2)).fit(data.text)
vectext = vectorizer.transform(data.text)
X_train, X_test, Y_train, Y_test = train_test_split(vectext,
targets,
random_state=0)
targets, targets.shape
(array([[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32), (5838, 7))
Above is our OHE form of target and we can see that there is at least one 1 in array’s each row and all are 0s. Also, the number of columns is 7, which represents total number of classes.
Simple Neural Network having one layer
First I want ot go through what is simple neural network. It is the most straightforward type of deep learning architecture. In this architecture, the source nodes in the input layer are directly connected to the neurons in the output layer (the computation nodes), but not the other way around. Simplest form of neural network is also known as perceptron. This type of neural network are mainly used for classification task. If our data is linearly separable then it is benificial to used percepton.
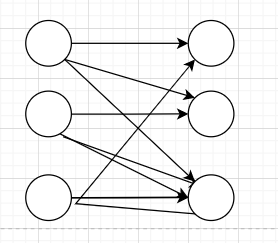
We use only one neuron to classify data of binary class. If we want to classify data of multiple class we should add more neurons in the output layer. If our data is not linearly separable then we can used multi level percepton having at least one hidden layer. However we can add as many hidden as we want. Adding more hidden layers help us to extract higher order statistics from input. Our news clsssification is a n example of non-linear example. The linearity also depends on the activation function that we use.
Since our target output is in one hot encoded form, we should use the activation function that takes probability into the consideration becasue in our one hot encoded labels, there will be 1 value in the class and 0 in off class. So our goal is to make the model predict as near as possible for each values.
# simple NN
in_shape = X_train.shape[-1]
out_shape = targets.shape[-1]
model = Sequential()
model.add(Dense(input_dim=9401, units=out_shape, activation='softmax'))
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 7) 65814
=================================================================
Total params: 65,814
Trainable params: 65,814
Non-trainable params: 0
_________________________________________________________________
In above block of code we build the model using sequential which allows us to build model using layer by layer. In this model there is input layer which has input numbers which is actually our vacabulary size similary we set unit 800, units is representing how many neurons in a particular layer we can change it’s value as how many we want. There is output layer which has only 6 outputs layer which means we want to classify our data into only 7 categories.
It is benifical to used softmax activation function in multiclass classification. In its most basic form, Softmax is a vector function. A vector is used as the input, and a vector is generated as the output. The outputs of each unit are likewise condensed by the Softmax algorithm to lie between 0 and 1. However, it also divides each result so that the aggregate of all the outputs equals 1. You may determine the likelihood that any of the classes is true from the output of the Softmax algorithm.
\begin{equation} softmax(x_j) = \frac{exp^{(x_j)}}{\sum_{i=1}^n{exp^{(x_i)}}} \end{equation}
If we do not mention any activation function by default there is use of linear activation function.
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
We shold always compile the model after build the model. We can view compilation as a precompute phase that enables the computer to train the model. While compliling the model we used ‘adam’ as optimizer. There are many other optimiser but which one is best to choose is crucial. Loss function as “categorical_crossentropy” because we have to classify our data into multiple classes.
Model Fit
history = model.fit(X_train.toarray(), Y_train, epochs=100, batch_size=32, validation_data=(X_test.toarray(), Y_test))
Epoch 1/100
137/137 [==============================] - 3s 6ms/step - loss: 1.7741 - accuracy: 0.5160 - val_loss: 1.6109 - val_accuracy: 0.6096
Epoch 2/100
137/137 [==============================] - 1s 4ms/step - loss: 1.4537 - accuracy: 0.6802 - val_loss: 1.3941 - val_accuracy: 0.6418
Epoch 3/100
137/137 [==============================] - 1s 4ms/step - loss: 1.2407 - accuracy: 0.7165 - val_loss: 1.2510 - val_accuracy: 0.6623
Epoch 4/100
137/137 [==============================] - 1s 4ms/step - loss: 1.0887 - accuracy: 0.7478 - val_loss: 1.1483 - val_accuracy: 0.6877
Epoch 5/100
137/137 [==============================] - 1s 4ms/step - loss: 0.9735 - accuracy: 0.7730 - val_loss: 1.0708 - val_accuracy: 0.7082
Epoch 6/100
137/137 [==============================] - 1s 4ms/step - loss: 0.8817 - accuracy: 0.7988 - val_loss: 1.0110 - val_accuracy: 0.7322
Epoch 7/100
137/137 [==============================] - 1s 4ms/step - loss: 0.8066 - accuracy: 0.8202 - val_loss: 0.9620 - val_accuracy: 0.7384
Epoch 8/100
137/137 [==============================] - 1s 4ms/step - loss: 0.7433 - accuracy: 0.8387 - val_loss: 0.9230 - val_accuracy: 0.7466
Epoch 9/100
137/137 [==============================] - 1s 5ms/step - loss: 0.6893 - accuracy: 0.8556 - val_loss: 0.8906 - val_accuracy: 0.7527
Epoch 10/100
137/137 [==============================] - 1s 4ms/step - loss: 0.6426 - accuracy: 0.8677 - val_loss: 0.8633 - val_accuracy: 0.7575
Epoch 11/100
137/137 [==============================] - 1s 4ms/step - loss: 0.6019 - accuracy: 0.8789 - val_loss: 0.8398 - val_accuracy: 0.7644
Epoch 12/100
137/137 [==============================] - 1s 5ms/step - loss: 0.5660 - accuracy: 0.8858 - val_loss: 0.8206 - val_accuracy: 0.7658
Epoch 13/100
137/137 [==============================] - 1s 8ms/step - loss: 0.5343 - accuracy: 0.8938 - val_loss: 0.8032 - val_accuracy: 0.7705
Epoch 14/100
137/137 [==============================] - 1s 4ms/step - loss: 0.5059 - accuracy: 0.8988 - val_loss: 0.7890 - val_accuracy: 0.7719
Epoch 15/100
137/137 [==============================] - 1s 4ms/step - loss: 0.4805 - accuracy: 0.9032 - val_loss: 0.7771 - val_accuracy: 0.7685
Epoch 16/100
137/137 [==============================] - 1s 4ms/step - loss: 0.4576 - accuracy: 0.9054 - val_loss: 0.7656 - val_accuracy: 0.7712
Epoch 17/100
137/137 [==============================] - 1s 4ms/step - loss: 0.4368 - accuracy: 0.9091 - val_loss: 0.7564 - val_accuracy: 0.7753
Epoch 18/100
137/137 [==============================] - 1s 4ms/step - loss: 0.4178 - accuracy: 0.9125 - val_loss: 0.7480 - val_accuracy: 0.7747
Epoch 19/100
137/137 [==============================] - 1s 4ms/step - loss: 0.4006 - accuracy: 0.9127 - val_loss: 0.7414 - val_accuracy: 0.7781
Epoch 20/100
137/137 [==============================] - 1s 4ms/step - loss: 0.3847 - accuracy: 0.9155 - val_loss: 0.7352 - val_accuracy: 0.7795
Epoch 21/100
137/137 [==============================] - 1s 4ms/step - loss: 0.3701 - accuracy: 0.9187 - val_loss: 0.7304 - val_accuracy: 0.7815
Epoch 22/100
137/137 [==============================] - 1s 4ms/step - loss: 0.3566 - accuracy: 0.9226 - val_loss: 0.7263 - val_accuracy: 0.7849
Epoch 23/100
137/137 [==============================] - 1s 4ms/step - loss: 0.3440 - accuracy: 0.9246 - val_loss: 0.7223 - val_accuracy: 0.7842
Epoch 24/100
137/137 [==============================] - 1s 4ms/step - loss: 0.3326 - accuracy: 0.9260 - val_loss: 0.7190 - val_accuracy: 0.7856
Epoch 25/100
137/137 [==============================] - 1s 5ms/step - loss: 0.3220 - accuracy: 0.9260 - val_loss: 0.7155 - val_accuracy: 0.7849
Epoch 26/100
137/137 [==============================] - 1s 4ms/step - loss: 0.3119 - accuracy: 0.9294 - val_loss: 0.7130 - val_accuracy: 0.7842
Epoch 27/100
137/137 [==============================] - 1s 4ms/step - loss: 0.3025 - accuracy: 0.9310 - val_loss: 0.7120 - val_accuracy: 0.7842
Epoch 28/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2938 - accuracy: 0.9317 - val_loss: 0.7104 - val_accuracy: 0.7836
Epoch 29/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2856 - accuracy: 0.9322 - val_loss: 0.7096 - val_accuracy: 0.7808
Epoch 30/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2780 - accuracy: 0.9317 - val_loss: 0.7088 - val_accuracy: 0.7822
Epoch 31/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2708 - accuracy: 0.9331 - val_loss: 0.7088 - val_accuracy: 0.7815
Epoch 32/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2638 - accuracy: 0.9338 - val_loss: 0.7084 - val_accuracy: 0.7822
Epoch 33/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2576 - accuracy: 0.9335 - val_loss: 0.7083 - val_accuracy: 0.7815
Epoch 34/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2518 - accuracy: 0.9331 - val_loss: 0.7090 - val_accuracy: 0.7788
Epoch 35/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2459 - accuracy: 0.9331 - val_loss: 0.7095 - val_accuracy: 0.7788
Epoch 36/100
137/137 [==============================] - 1s 5ms/step - loss: 0.2407 - accuracy: 0.9347 - val_loss: 0.7106 - val_accuracy: 0.7788
Epoch 37/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2355 - accuracy: 0.9344 - val_loss: 0.7112 - val_accuracy: 0.7808
Epoch 38/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2306 - accuracy: 0.9338 - val_loss: 0.7135 - val_accuracy: 0.7808
Epoch 39/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2262 - accuracy: 0.9338 - val_loss: 0.7145 - val_accuracy: 0.7808
Epoch 40/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2219 - accuracy: 0.9347 - val_loss: 0.7161 - val_accuracy: 0.7795
Epoch 41/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2176 - accuracy: 0.9354 - val_loss: 0.7176 - val_accuracy: 0.7788
Epoch 42/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2139 - accuracy: 0.9351 - val_loss: 0.7197 - val_accuracy: 0.7795
Epoch 43/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2100 - accuracy: 0.9340 - val_loss: 0.7214 - val_accuracy: 0.7781
Epoch 44/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2066 - accuracy: 0.9342 - val_loss: 0.7237 - val_accuracy: 0.7774
Epoch 45/100
137/137 [==============================] - 1s 4ms/step - loss: 0.2032 - accuracy: 0.9344 - val_loss: 0.7259 - val_accuracy: 0.7767
Epoch 46/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1999 - accuracy: 0.9351 - val_loss: 0.7279 - val_accuracy: 0.7774
Epoch 47/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1969 - accuracy: 0.9340 - val_loss: 0.7301 - val_accuracy: 0.7795
Epoch 48/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1940 - accuracy: 0.9367 - val_loss: 0.7329 - val_accuracy: 0.7781
Epoch 49/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1912 - accuracy: 0.9349 - val_loss: 0.7353 - val_accuracy: 0.7781
Epoch 50/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1887 - accuracy: 0.9344 - val_loss: 0.7382 - val_accuracy: 0.7774
Epoch 51/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1861 - accuracy: 0.9340 - val_loss: 0.7406 - val_accuracy: 0.7774
Epoch 52/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1836 - accuracy: 0.9370 - val_loss: 0.7432 - val_accuracy: 0.7774
Epoch 53/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1814 - accuracy: 0.9338 - val_loss: 0.7467 - val_accuracy: 0.7801
Epoch 54/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1790 - accuracy: 0.9333 - val_loss: 0.7492 - val_accuracy: 0.7815
Epoch 55/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1770 - accuracy: 0.9363 - val_loss: 0.7520 - val_accuracy: 0.7815
Epoch 56/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1750 - accuracy: 0.9351 - val_loss: 0.7555 - val_accuracy: 0.7788
Epoch 57/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1731 - accuracy: 0.9340 - val_loss: 0.7588 - val_accuracy: 0.7808
Epoch 58/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1710 - accuracy: 0.9347 - val_loss: 0.7619 - val_accuracy: 0.7808
Epoch 59/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1691 - accuracy: 0.9360 - val_loss: 0.7651 - val_accuracy: 0.7815
Epoch 60/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1674 - accuracy: 0.9347 - val_loss: 0.7686 - val_accuracy: 0.7808
Epoch 61/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1659 - accuracy: 0.9344 - val_loss: 0.7718 - val_accuracy: 0.7815
Epoch 62/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1642 - accuracy: 0.9342 - val_loss: 0.7748 - val_accuracy: 0.7842
Epoch 63/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1628 - accuracy: 0.9360 - val_loss: 0.7787 - val_accuracy: 0.7836
Epoch 64/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1613 - accuracy: 0.9335 - val_loss: 0.7823 - val_accuracy: 0.7849
Epoch 65/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1599 - accuracy: 0.9356 - val_loss: 0.7855 - val_accuracy: 0.7856
Epoch 66/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1585 - accuracy: 0.9367 - val_loss: 0.7888 - val_accuracy: 0.7849
Epoch 67/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1572 - accuracy: 0.9342 - val_loss: 0.7932 - val_accuracy: 0.7863
Epoch 68/100
137/137 [==============================] - 1s 8ms/step - loss: 0.1559 - accuracy: 0.9354 - val_loss: 0.7968 - val_accuracy: 0.7849
Epoch 69/100
137/137 [==============================] - 1s 6ms/step - loss: 0.1546 - accuracy: 0.9381 - val_loss: 0.8002 - val_accuracy: 0.7856
Epoch 70/100
137/137 [==============================] - 1s 6ms/step - loss: 0.1535 - accuracy: 0.9338 - val_loss: 0.8037 - val_accuracy: 0.7856
Epoch 71/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1523 - accuracy: 0.9349 - val_loss: 0.8071 - val_accuracy: 0.7842
Epoch 72/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1514 - accuracy: 0.9347 - val_loss: 0.8110 - val_accuracy: 0.7849
Epoch 73/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1503 - accuracy: 0.9344 - val_loss: 0.8150 - val_accuracy: 0.7849
Epoch 74/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1493 - accuracy: 0.9347 - val_loss: 0.8190 - val_accuracy: 0.7870
Epoch 75/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1484 - accuracy: 0.9356 - val_loss: 0.8224 - val_accuracy: 0.7842
Epoch 76/100
137/137 [==============================] - 1s 5ms/step - loss: 0.1474 - accuracy: 0.9358 - val_loss: 0.8271 - val_accuracy: 0.7856
Epoch 77/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1463 - accuracy: 0.9335 - val_loss: 0.8310 - val_accuracy: 0.7849
Epoch 78/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1455 - accuracy: 0.9349 - val_loss: 0.8349 - val_accuracy: 0.7863
Epoch 79/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1448 - accuracy: 0.9342 - val_loss: 0.8389 - val_accuracy: 0.7877
Epoch 80/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1439 - accuracy: 0.9342 - val_loss: 0.8428 - val_accuracy: 0.7863
Epoch 81/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1430 - accuracy: 0.9326 - val_loss: 0.8474 - val_accuracy: 0.7856
Epoch 82/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1423 - accuracy: 0.9354 - val_loss: 0.8513 - val_accuracy: 0.7863
Epoch 83/100
137/137 [==============================] - 1s 5ms/step - loss: 0.1416 - accuracy: 0.9354 - val_loss: 0.8560 - val_accuracy: 0.7836
Epoch 84/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1409 - accuracy: 0.9379 - val_loss: 0.8595 - val_accuracy: 0.7849
Epoch 85/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1403 - accuracy: 0.9354 - val_loss: 0.8633 - val_accuracy: 0.7836
Epoch 86/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1394 - accuracy: 0.9333 - val_loss: 0.8678 - val_accuracy: 0.7836
Epoch 87/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1389 - accuracy: 0.9349 - val_loss: 0.8727 - val_accuracy: 0.7842
Epoch 88/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1382 - accuracy: 0.9351 - val_loss: 0.8763 - val_accuracy: 0.7842
Epoch 89/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1378 - accuracy: 0.9351 - val_loss: 0.8805 - val_accuracy: 0.7849
Epoch 90/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1370 - accuracy: 0.9338 - val_loss: 0.8851 - val_accuracy: 0.7836
Epoch 91/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1365 - accuracy: 0.9338 - val_loss: 0.8884 - val_accuracy: 0.7849
Epoch 92/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1358 - accuracy: 0.9365 - val_loss: 0.8933 - val_accuracy: 0.7842
Epoch 93/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1354 - accuracy: 0.9374 - val_loss: 0.8968 - val_accuracy: 0.7842
Epoch 94/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1348 - accuracy: 0.9349 - val_loss: 0.9014 - val_accuracy: 0.7849
Epoch 95/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1345 - accuracy: 0.9347 - val_loss: 0.9061 - val_accuracy: 0.7836
Epoch 96/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1338 - accuracy: 0.9367 - val_loss: 0.9104 - val_accuracy: 0.7836
Epoch 97/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1332 - accuracy: 0.9351 - val_loss: 0.9144 - val_accuracy: 0.7856
Epoch 98/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1330 - accuracy: 0.9356 - val_loss: 0.9193 - val_accuracy: 0.7849
Epoch 99/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1323 - accuracy: 0.9347 - val_loss: 0.9237 - val_accuracy: 0.7836
Epoch 100/100
137/137 [==============================] - 1s 4ms/step - loss: 0.1319 - accuracy: 0.9360 - val_loss: 0.9278 - val_accuracy: 0.7842
Finally, we fit the model using required arguments for our model. Firt we need to provide train data to our model. In above while training the model I used .toarray() function because to fit model we need array of data but before used toarray() function we have sparse matrix. If we do not used toarray function we can get error message.
We can set epoch here 100 it means model can go up to 100 iteration however we can set it 20, 25 also if model already fit well up to 20 iteration it can obviously give right performance we set it upto 32,40 so on then there is possibility to overfit our model. Hence right choice of epochs size is also crucial.
Similarly in above example we set batch_size 32. Batch size allow us to split the total data into 32 parts calculate the gardient at different part and finally aggrigate the results of each batch. If we set batch size higher number it takes grater time to train the model and voice versa.
Performance of model
In above example we tarin the model by only using input and output layer. Our model do work preety well. Our accuracy as well as validation accuracy goes on at satisfiable level. If we look towards loss it goes on decreaing at each iterations.
def performance_model(hist, model, X_test, Y_test, classes):
# subplot
fig, axes = plt.subplots(1,2, figsize=(20,5))
axes[0].set_title('Accuracy score')
axes[0].plot(history.history['accuracy'])
axes[0].plot(history.history['val_accuracy'])
axes[0].legend(['accuracy', 'val_accuracy'])
# plt.show()
# plt.figure(figsize=(9,7))
axes[1].set_title('Loss value')
axes[1].plot(history.history['loss'])
axes[1].plot(history.history['val_loss'])
axes[1].legend(['loss', 'val_loss'])
plt.show()
predictions = model.predict(X_test.toarray())
y_test_evaluate = np.argmax(Y_test, axis=1)
pred = np.argmax(predictions, axis=1)
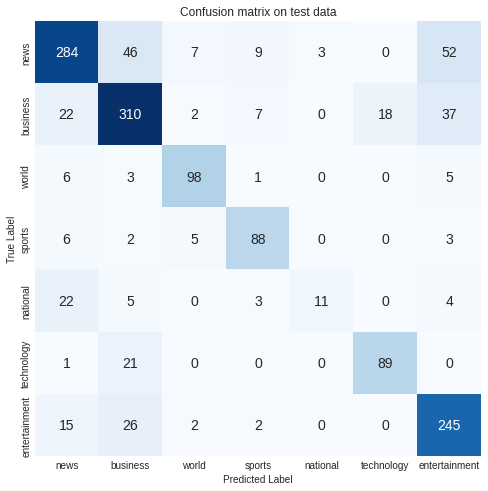
cm = confusion_matrix(y_test_evaluate, pred)
plt.figure(figsize=(8,8))
plt.title('Confusion matrix on test data')
sns.heatmap(cm, annot=True, fmt='d', xticklabels=classes.keys(), yticklabels=classes.keys(),
cmap=plt.cm.Blues, cbar=False, annot_kws={'size':14})
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()
performance_model(history, model, X_test, Y_test, classes)
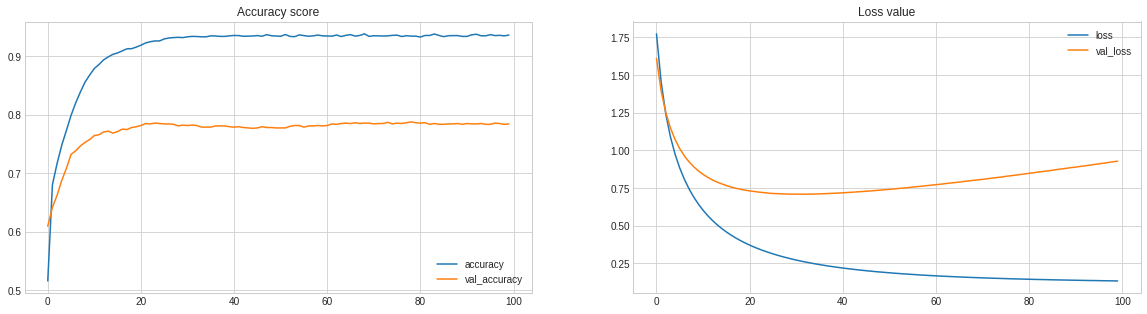
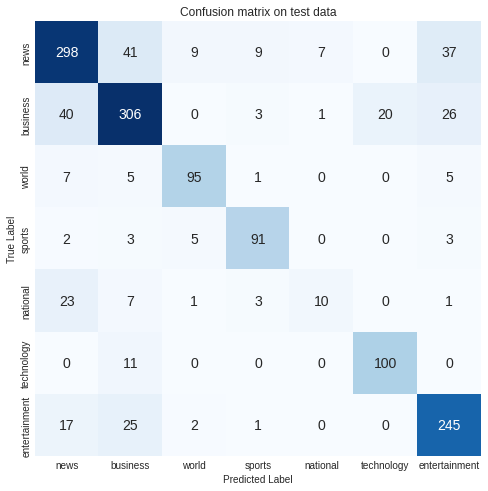
The above graph shows that our accuracy and validation accuracy are both increasing significantly, but there is a significant gap between the two.It may be possible to happen for the following reasons:
- A class imbalance
- Underfitting
- Overfitting
- In precise preprocessing
Similarily, in our classification problem, accuracy is not a good measure of model perfarmance because our model has multiple classes as well, and there may be a case of class imbalance. Hence, to evaluate our model performance, we used the multicalss confusion matrix. In multiclass classification problems, the f1 score will be a better measure of model performance.
Adding one more hidden layer
Lets explore our model adding one hidden layer in between input layer and output layer and compare the performance of model from previous one.
# simple NN with one hidden layer
model = Sequential()
model.add(Dense(input_dim=9401, units=800))
model.add(Dense(800))
model.add(Dense(out_shape, activation='softmax'))
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 800) 7521600
dense_2 (Dense) (None, 800) 640800
dense_3 (Dense) (None, 7) 5607
=================================================================
Total params: 8,168,007
Trainable params: 8,168,007
Non-trainable params: 0
_________________________________________________________________
In above model we use all same but we add one extra hidden layer which has 800 units which means there are 800 neurons.
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
Lets fit model.
history = model.fit(X_train.toarray(), Y_train, epochs=100, batch_size=35, validation_data=(X_test.toarray(), Y_test))
Epoch 1/100
126/126 [==============================] - 1s 8ms/step - loss: 1.0233 - accuracy: 0.6690 - val_loss: 0.7602 - val_accuracy: 0.7658
Epoch 2/100
126/126 [==============================] - 1s 7ms/step - loss: 0.3653 - accuracy: 0.8956 - val_loss: 0.8770 - val_accuracy: 0.7630
Epoch 3/100
126/126 [==============================] - 1s 6ms/step - loss: 0.2748 - accuracy: 0.9143 - val_loss: 0.8179 - val_accuracy: 0.7719
Epoch 4/100
126/126 [==============================] - 1s 6ms/step - loss: 0.2407 - accuracy: 0.9233 - val_loss: 0.8869 - val_accuracy: 0.7616
Epoch 5/100
126/126 [==============================] - 1s 6ms/step - loss: 0.2325 - accuracy: 0.9203 - val_loss: 0.8362 - val_accuracy: 0.7849
Epoch 6/100
126/126 [==============================] - 1s 6ms/step - loss: 0.2135 - accuracy: 0.9230 - val_loss: 0.8728 - val_accuracy: 0.7733
Epoch 7/100
126/126 [==============================] - 1s 6ms/step - loss: 0.2102 - accuracy: 0.9255 - val_loss: 0.8760 - val_accuracy: 0.7788
Epoch 8/100
126/126 [==============================] - 1s 6ms/step - loss: 0.2127 - accuracy: 0.9251 - val_loss: 0.9314 - val_accuracy: 0.7466
Epoch 9/100
126/126 [==============================] - 1s 6ms/step - loss: 0.2107 - accuracy: 0.9230 - val_loss: 1.0136 - val_accuracy: 0.7616
Epoch 10/100
126/126 [==============================] - 1s 8ms/step - loss: 0.2009 - accuracy: 0.9274 - val_loss: 0.9555 - val_accuracy: 0.7692
Epoch 11/100
126/126 [==============================] - 1s 9ms/step - loss: 0.1977 - accuracy: 0.9274 - val_loss: 0.9830 - val_accuracy: 0.7781
Epoch 12/100
126/126 [==============================] - 1s 9ms/step - loss: 0.1908 - accuracy: 0.9278 - val_loss: 0.9244 - val_accuracy: 0.7555
Epoch 13/100
126/126 [==============================] - 1s 7ms/step - loss: 0.1828 - accuracy: 0.9258 - val_loss: 0.9641 - val_accuracy: 0.7548
Epoch 14/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1740 - accuracy: 0.9301 - val_loss: 1.0089 - val_accuracy: 0.7630
Epoch 15/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1811 - accuracy: 0.9301 - val_loss: 0.9290 - val_accuracy: 0.7603
Epoch 16/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1690 - accuracy: 0.9322 - val_loss: 0.9671 - val_accuracy: 0.7493
Epoch 17/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1743 - accuracy: 0.9280 - val_loss: 1.0466 - val_accuracy: 0.7822
Epoch 18/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1785 - accuracy: 0.9294 - val_loss: 1.2220 - val_accuracy: 0.7500
Epoch 19/100
126/126 [==============================] - 1s 6ms/step - loss: 0.2090 - accuracy: 0.9260 - val_loss: 1.1526 - val_accuracy: 0.7514
Epoch 20/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1936 - accuracy: 0.9310 - val_loss: 1.0568 - val_accuracy: 0.7459
Epoch 21/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1746 - accuracy: 0.9278 - val_loss: 1.0345 - val_accuracy: 0.7527
Epoch 22/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1600 - accuracy: 0.9326 - val_loss: 1.0820 - val_accuracy: 0.7740
Epoch 23/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1823 - accuracy: 0.9278 - val_loss: 0.9914 - val_accuracy: 0.7664
Epoch 24/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1770 - accuracy: 0.9331 - val_loss: 1.0346 - val_accuracy: 0.7719
Epoch 25/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1738 - accuracy: 0.9342 - val_loss: 1.0696 - val_accuracy: 0.7678
Epoch 26/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1678 - accuracy: 0.9310 - val_loss: 1.0201 - val_accuracy: 0.7692
Epoch 27/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1551 - accuracy: 0.9340 - val_loss: 1.0547 - val_accuracy: 0.7521
Epoch 28/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1590 - accuracy: 0.9338 - val_loss: 0.9871 - val_accuracy: 0.7699
Epoch 29/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1527 - accuracy: 0.9340 - val_loss: 1.0202 - val_accuracy: 0.7767
Epoch 30/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1560 - accuracy: 0.9290 - val_loss: 1.0242 - val_accuracy: 0.7658
Epoch 31/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1507 - accuracy: 0.9326 - val_loss: 0.9984 - val_accuracy: 0.7781
Epoch 32/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1521 - accuracy: 0.9310 - val_loss: 1.0071 - val_accuracy: 0.7753
Epoch 33/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1542 - accuracy: 0.9322 - val_loss: 1.0931 - val_accuracy: 0.7644
Epoch 34/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1584 - accuracy: 0.9328 - val_loss: 1.0295 - val_accuracy: 0.7760
Epoch 35/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1521 - accuracy: 0.9324 - val_loss: 1.0787 - val_accuracy: 0.7801
Epoch 36/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1527 - accuracy: 0.9370 - val_loss: 1.0878 - val_accuracy: 0.7788
Epoch 37/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1695 - accuracy: 0.9317 - val_loss: 1.1328 - val_accuracy: 0.7685
Epoch 38/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1639 - accuracy: 0.9283 - val_loss: 1.0733 - val_accuracy: 0.7664
Epoch 39/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1525 - accuracy: 0.9322 - val_loss: 1.1290 - val_accuracy: 0.7829
Epoch 40/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1505 - accuracy: 0.9347 - val_loss: 1.0747 - val_accuracy: 0.7781
Epoch 41/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1483 - accuracy: 0.9319 - val_loss: 1.0657 - val_accuracy: 0.7671
Epoch 42/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1482 - accuracy: 0.9335 - val_loss: 1.0446 - val_accuracy: 0.7685
Epoch 43/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1424 - accuracy: 0.9349 - val_loss: 1.0357 - val_accuracy: 0.7863
Epoch 44/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1530 - accuracy: 0.9312 - val_loss: 1.3468 - val_accuracy: 0.7521
Epoch 45/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1688 - accuracy: 0.9296 - val_loss: 1.2449 - val_accuracy: 0.7589
Epoch 46/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1566 - accuracy: 0.9319 - val_loss: 1.1356 - val_accuracy: 0.7678
Epoch 47/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1547 - accuracy: 0.9322 - val_loss: 1.0903 - val_accuracy: 0.7644
Epoch 48/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1478 - accuracy: 0.9303 - val_loss: 1.0850 - val_accuracy: 0.7637
Epoch 49/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1443 - accuracy: 0.9335 - val_loss: 1.0880 - val_accuracy: 0.7562
Epoch 50/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1442 - accuracy: 0.9312 - val_loss: 1.0931 - val_accuracy: 0.7815
Epoch 51/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1503 - accuracy: 0.9349 - val_loss: 1.0529 - val_accuracy: 0.7630
Epoch 52/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1448 - accuracy: 0.9324 - val_loss: 1.0910 - val_accuracy: 0.7658
Epoch 53/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1444 - accuracy: 0.9290 - val_loss: 1.0953 - val_accuracy: 0.7692
Epoch 54/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1427 - accuracy: 0.9335 - val_loss: 1.0905 - val_accuracy: 0.7726
Epoch 55/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1402 - accuracy: 0.9358 - val_loss: 1.1630 - val_accuracy: 0.7664
Epoch 56/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1372 - accuracy: 0.9358 - val_loss: 1.2109 - val_accuracy: 0.7678
Epoch 57/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1468 - accuracy: 0.9322 - val_loss: 1.1316 - val_accuracy: 0.7568
Epoch 58/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1442 - accuracy: 0.9335 - val_loss: 1.1098 - val_accuracy: 0.7582
Epoch 59/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1422 - accuracy: 0.9335 - val_loss: 1.1099 - val_accuracy: 0.7582
Epoch 60/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1409 - accuracy: 0.9340 - val_loss: 1.0642 - val_accuracy: 0.7719
Epoch 61/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1413 - accuracy: 0.9356 - val_loss: 1.1239 - val_accuracy: 0.7678
Epoch 62/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1424 - accuracy: 0.9338 - val_loss: 1.1617 - val_accuracy: 0.7637
Epoch 63/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1447 - accuracy: 0.9306 - val_loss: 1.0902 - val_accuracy: 0.7603
Epoch 64/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1515 - accuracy: 0.9342 - val_loss: 1.1615 - val_accuracy: 0.7630
Epoch 65/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1452 - accuracy: 0.9340 - val_loss: 1.1811 - val_accuracy: 0.7603
Epoch 66/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1404 - accuracy: 0.9338 - val_loss: 1.1923 - val_accuracy: 0.7678
Epoch 67/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1387 - accuracy: 0.9372 - val_loss: 1.1625 - val_accuracy: 0.7671
Epoch 68/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1384 - accuracy: 0.9328 - val_loss: 1.1772 - val_accuracy: 0.7678
Epoch 69/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1445 - accuracy: 0.9333 - val_loss: 1.1646 - val_accuracy: 0.7719
Epoch 70/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1409 - accuracy: 0.9317 - val_loss: 1.1859 - val_accuracy: 0.7733
Epoch 71/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1363 - accuracy: 0.9340 - val_loss: 1.1493 - val_accuracy: 0.7767
Epoch 72/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1413 - accuracy: 0.9347 - val_loss: 1.1126 - val_accuracy: 0.7705
Epoch 73/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1395 - accuracy: 0.9335 - val_loss: 1.1422 - val_accuracy: 0.7637
Epoch 74/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1485 - accuracy: 0.9358 - val_loss: 1.4028 - val_accuracy: 0.7541
Epoch 75/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1518 - accuracy: 0.9354 - val_loss: 1.4361 - val_accuracy: 0.7726
Epoch 76/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1571 - accuracy: 0.9335 - val_loss: 1.3987 - val_accuracy: 0.7589
Epoch 77/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1570 - accuracy: 0.9347 - val_loss: 1.3393 - val_accuracy: 0.7637
Epoch 78/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1512 - accuracy: 0.9347 - val_loss: 1.3479 - val_accuracy: 0.7623
Epoch 79/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1458 - accuracy: 0.9331 - val_loss: 1.3049 - val_accuracy: 0.7562
Epoch 80/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1479 - accuracy: 0.9340 - val_loss: 1.3393 - val_accuracy: 0.7644
Epoch 81/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1394 - accuracy: 0.9386 - val_loss: 1.2484 - val_accuracy: 0.7671
Epoch 82/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1391 - accuracy: 0.9370 - val_loss: 1.2412 - val_accuracy: 0.7644
Epoch 83/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1368 - accuracy: 0.9365 - val_loss: 1.2545 - val_accuracy: 0.7664
Epoch 84/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1427 - accuracy: 0.9340 - val_loss: 1.2018 - val_accuracy: 0.7603
Epoch 85/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1325 - accuracy: 0.9372 - val_loss: 1.2868 - val_accuracy: 0.7651
Epoch 86/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1362 - accuracy: 0.9349 - val_loss: 1.2306 - val_accuracy: 0.7658
Epoch 87/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1338 - accuracy: 0.9333 - val_loss: 1.2871 - val_accuracy: 0.7616
Epoch 88/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1367 - accuracy: 0.9331 - val_loss: 1.2153 - val_accuracy: 0.7836
Epoch 89/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1351 - accuracy: 0.9363 - val_loss: 1.2591 - val_accuracy: 0.7699
Epoch 90/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1315 - accuracy: 0.9349 - val_loss: 1.2360 - val_accuracy: 0.7616
Epoch 91/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1317 - accuracy: 0.9372 - val_loss: 1.3478 - val_accuracy: 0.7534
Epoch 92/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1383 - accuracy: 0.9317 - val_loss: 1.2972 - val_accuracy: 0.7685
Epoch 93/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1365 - accuracy: 0.9349 - val_loss: 1.2775 - val_accuracy: 0.7562
Epoch 94/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1374 - accuracy: 0.9406 - val_loss: 1.2316 - val_accuracy: 0.7644
Epoch 95/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1352 - accuracy: 0.9338 - val_loss: 1.2494 - val_accuracy: 0.7630
Epoch 96/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1555 - accuracy: 0.9370 - val_loss: 1.3208 - val_accuracy: 0.7548
Epoch 97/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1346 - accuracy: 0.9360 - val_loss: 1.2599 - val_accuracy: 0.7651
Epoch 98/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1382 - accuracy: 0.9363 - val_loss: 1.2476 - val_accuracy: 0.7616
Epoch 99/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1324 - accuracy: 0.9344 - val_loss: 1.2851 - val_accuracy: 0.7637
Epoch 100/100
126/126 [==============================] - 1s 6ms/step - loss: 0.1432 - accuracy: 0.9358 - val_loss: 1.2710 - val_accuracy: 0.7664
performance_model(history, model, X_test, Y_test, classes)
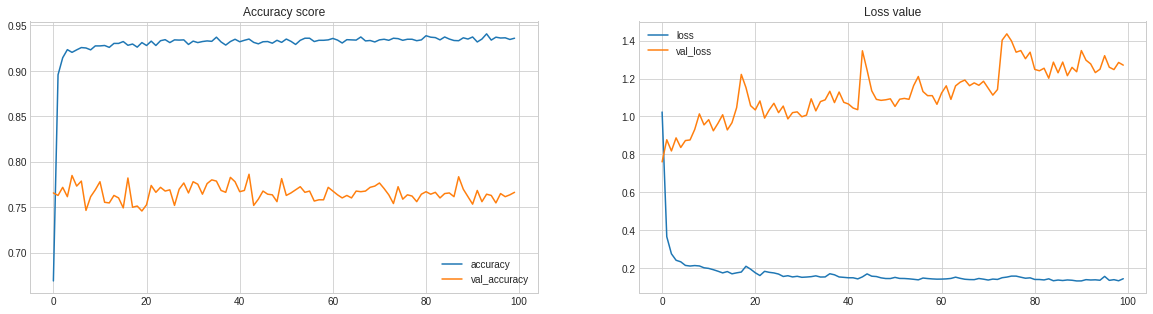
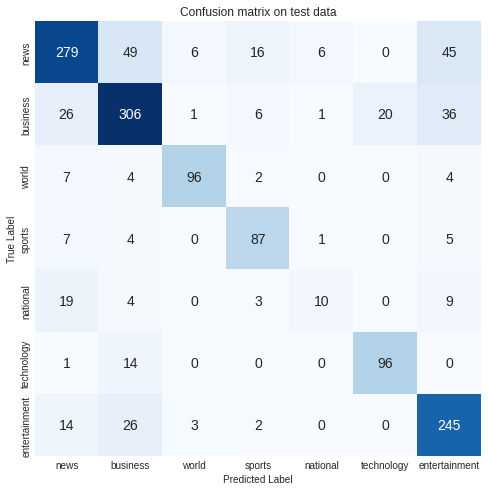
Compare to the previous one our model get fluctuate due to overfitting or it may happen due to under fitting. Let’s add some dropeout. Drouptout is used to regulate our model in case of oaverfitting.
# simple NN
model = Sequential()
model.add(Dense(input_dim=in_shape, units=800))
model.add(Dense(800))
model.add(Dropout(0.5))
model.add(Dense(out_shape, activation='softmax'))
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 800) 7521600
dense_5 (Dense) (None, 800) 640800
dropout (Dropout) (None, 800) 0
dense_6 (Dense) (None, 7) 5607
=================================================================
Total params: 8,168,007
Trainable params: 8,168,007
Non-trainable params: 0
_________________________________________________________________
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(X_train.toarray(), Y_train, epochs=10, batch_size=32, validation_data=(X_test.toarray(), Y_test))
Epoch 1/10
137/137 [==============================] - 2s 8ms/step - loss: 1.0331 - accuracy: 0.6592 - val_loss: 0.7495 - val_accuracy: 0.7630
Epoch 2/10
137/137 [==============================] - 1s 6ms/step - loss: 0.3937 - accuracy: 0.8856 - val_loss: 0.8275 - val_accuracy: 0.7719
Epoch 3/10
137/137 [==============================] - 1s 6ms/step - loss: 0.3173 - accuracy: 0.9100 - val_loss: 0.8168 - val_accuracy: 0.7747
Epoch 4/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2610 - accuracy: 0.9223 - val_loss: 0.8826 - val_accuracy: 0.7877
Epoch 5/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2415 - accuracy: 0.9258 - val_loss: 0.8702 - val_accuracy: 0.7740
Epoch 6/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2325 - accuracy: 0.9267 - val_loss: 0.9430 - val_accuracy: 0.7630
Epoch 7/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2360 - accuracy: 0.9212 - val_loss: 0.9362 - val_accuracy: 0.7781
Epoch 8/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2266 - accuracy: 0.9233 - val_loss: 0.9364 - val_accuracy: 0.7815
Epoch 9/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2180 - accuracy: 0.9246 - val_loss: 0.8815 - val_accuracy: 0.7747
Epoch 10/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2200 - accuracy: 0.9269 - val_loss: 0.8999 - val_accuracy: 0.7822
performance_model(history, model, X_test, Y_test, classes)
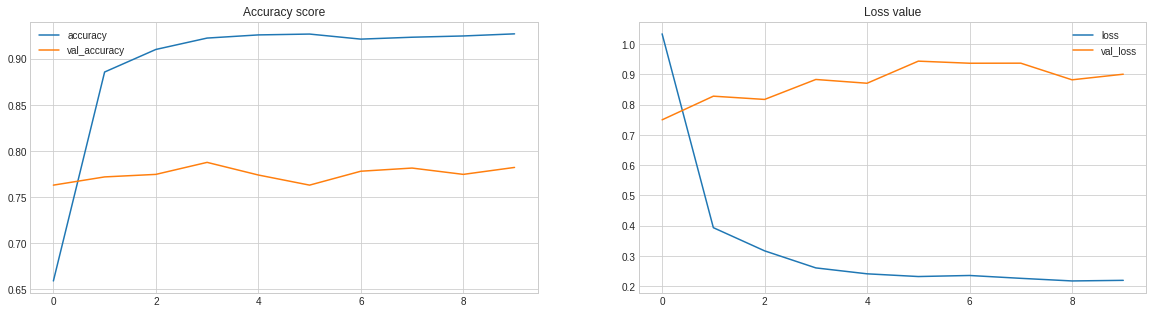
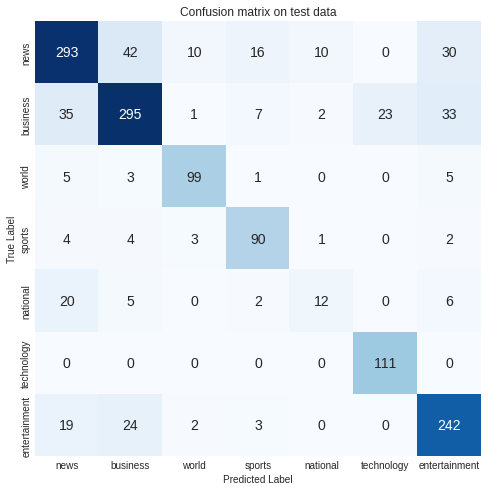
After Dropout added our model does preetry well. In above block of code we also reduce epoch to get better performance of our model.
Let’s Add few more Layer, Dropout and Observe the result
# simple NN
model = Sequential()
model.add(Dense(input_dim=in_shape, units=800))
model.add(Dense(800))
model.add(Dropout(0.2))
model.add(Dense(400))
#model.add(Dropout(0.2))
model.add(Dense(out_shape, activation='softmax'))
model.summary()
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_11 (Dense) (None, 800) 7521600
dense_12 (Dense) (None, 800) 640800
dropout_2 (Dropout) (None, 800) 0
dense_13 (Dense) (None, 400) 320400
dense_14 (Dense) (None, 7) 2807
=================================================================
Total params: 8,485,607
Trainable params: 8,485,607
Non-trainable params: 0
_________________________________________________________________
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(X_train.toarray(), Y_train, epochs=10, batch_size=32, validation_data=(X_test.toarray(), Y_test))
Epoch 1/10
137/137 [==============================] - 2s 9ms/step - loss: 1.0494 - accuracy: 0.6585 - val_loss: 0.7984 - val_accuracy: 0.7610
Epoch 2/10
137/137 [==============================] - 1s 6ms/step - loss: 0.4105 - accuracy: 0.8862 - val_loss: 0.9538 - val_accuracy: 0.7534
Epoch 3/10
137/137 [==============================] - 1s 6ms/step - loss: 0.3477 - accuracy: 0.9091 - val_loss: 0.9417 - val_accuracy: 0.7445
Epoch 4/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2813 - accuracy: 0.9175 - val_loss: 0.9003 - val_accuracy: 0.7781
Epoch 5/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2623 - accuracy: 0.9217 - val_loss: 0.8869 - val_accuracy: 0.7767
Epoch 6/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2364 - accuracy: 0.9219 - val_loss: 0.8637 - val_accuracy: 0.7760
Epoch 7/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2442 - accuracy: 0.9221 - val_loss: 0.9527 - val_accuracy: 0.7932
Epoch 8/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2369 - accuracy: 0.9203 - val_loss: 0.9556 - val_accuracy: 0.7733
Epoch 9/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2210 - accuracy: 0.9233 - val_loss: 0.9772 - val_accuracy: 0.7808
Epoch 10/10
137/137 [==============================] - 1s 6ms/step - loss: 0.2238 - accuracy: 0.9258 - val_loss: 0.9673 - val_accuracy: 0.7705
performance_model(history, model, X_test, Y_test, classes)
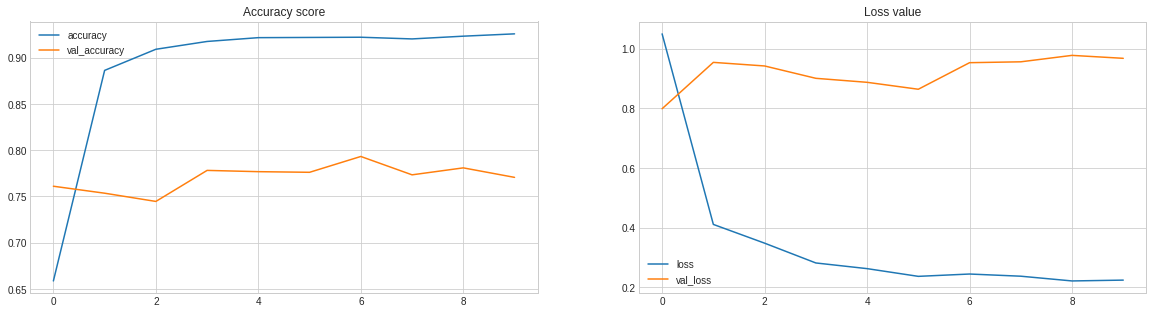
Conclusion:
The above graph shows that our accuracy and validation accuracy are both increasing significantly, but there is a significant gap between the two.It may be possible to happen for the following reasons:
- A class imbalance
- Underfitting
- Overfitting
- In precise preprocessing Hence we can improve our model and get better performance by adding mode training data and by better preprocessing(we have only limited amount of stop words).


Comments