
Basic Introduction Of GRU
There are two primary issues with recurrent neural networks
-
Calculations of gradients either fail or explode.
-
Gradient calculations are expensive
Gradient clipping is a solution to the expanding gradient problem, and other topologies like the gated recurrent unit (GRU) network and the Long Short-Term Memory (LSTM) network are solutions to the vanishing gradient problem. Both GRU and LSTM are RNN architecture variations. Use of the reduced BPTT method is the solution to the second issue.
Import
Here we import necessary module which we required while Fitting LSTM model on Commercial data.
pandas : For data analysis and data manipulation
numpy : for array manipulation and able to work with array type data
matplotlib: For data visualization and analysis of data
cufflinks : for making interactive plot with pandas data
` keras` : to fit GRU model using keras library
import pandas as pd
import numpy as np
from keras import Sequential
from keras.layers import GRU, Dense, Dropout
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
import cufflinks
cufflinks.go_offline()
cufflinks.set_config_file(world_readable=True, theme='pearl')
Read Data
This specific data is acquired from GitHub, which houses numerous csv files from various businesses. However, I used data from a commercial bank for this LSTM model. There are 2572 rows in all.
commerce = pd.read_csv("E:/code/Machine learing/ML Last Assignment/Commercial Bank/ADBL_2000-01-01_2021-12-31.csv", engine='python')
commerce.head()
| S.N. | Date | Total Transactions | Total Traded Shares | Total Traded Amount | Max. Price | Min. Price | Close Price | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2021-12-29 | 1013 | 200533.0 | 98526860.8 | 499.0 | 488.0 | 492.0 |
| 1 | 2 | 2021-12-28 | 659 | 91046.0 | 44737396.5 | 498.0 | 488.0 | 494.0 |
| 2 | 3 | 2021-12-27 | 816 | 88858.0 | 44186856.3 | 510.0 | 491.0 | 493.0 |
| 3 | 4 | 2021-12-26 | 1002 | 130801.0 | 65306688.9 | 502.0 | 495.0 | 500.0 |
| 4 | 5 | 2021-12-23 | 714 | 77234.0 | 38044401.2 | 497.0 | 481.0 | 496.0 |
commerce.shape
(2572, 8)
# Sort Data in Ascending order Our data is arranged according to time in descending order. In order to maintain our data in rising order according to our date property, we here change the given data into ascending order. Using the built-in function head, we were able to only examine a portion of the given data set (). We can only access the top 5 data points of the provided dataset by utilizing this head function.
commerce = commerce.sort_values(by="Date")
commerce.head()
| S.N. | Date | Total Transactions | Total Traded Shares | Total Traded Amount | Max. Price | Min. Price | Close Price | |
|---|---|---|---|---|---|---|---|---|
| 2571 | 2572 | 2010-08-26 | 2 | 40.0 | 10150.0 | 255.0 | 250.0 | 250.0 |
| 2570 | 2571 | 2010-08-29 | 2 | 20.0 | 4860.0 | 245.0 | 241.0 | 241.0 |
| 2569 | 2570 | 2010-08-30 | 6 | 60.0 | 13620.0 | 237.0 | 217.0 | 217.0 |
| 2568 | 2569 | 2010-08-31 | 6 | 60.0 | 12210.0 | 213.0 | 196.0 | 196.0 |
| 2567 | 2568 | 2010-09-02 | 6 | 60.0 | 11130.0 | 193.0 | 178.0 | 178.0 |
Handle Missing NAs
Our analysis might not be successful if there are any missing values. Therefore, we need look for missing values to make our data clean and able to be evaluated. If necessary, we can substitute the missing value with the prior or following value using the average of the other values. However, we ignore the missing data in this instance.
#Handle missing data by dropinig NAs.
commerce = commerce.dropna()
commerce.tail()
| S.N. | Date | Total Transactions | Total Traded Shares | Total Traded Amount | Max. Price | Min. Price | Close Price | |
|---|---|---|---|---|---|---|---|---|
| 4 | 5 | 2021-12-23 | 714 | 77234.0 | 38044401.2 | 497.0 | 481.0 | 496.0 |
| 3 | 4 | 2021-12-26 | 1002 | 130801.0 | 65306688.9 | 502.0 | 495.0 | 500.0 |
| 2 | 3 | 2021-12-27 | 816 | 88858.0 | 44186856.3 | 510.0 | 491.0 | 493.0 |
| 1 | 2 | 2021-12-28 | 659 | 91046.0 | 44737396.5 | 498.0 | 488.0 | 494.0 |
| 0 | 1 | 2021-12-29 | 1013 | 200533.0 | 98526860.8 | 499.0 | 488.0 | 492.0 |
Plot Trend
Here, we plot our statistics to see how they are trending. by keeping the data in the line plot’s horizontal axis and the closing price in its vertical axis. We are aware that time series data is information that varies over time. As a result, they lack a steady trend.
commerce.iplot(kind="line",x="Date",y="Close Price",xTitle="Date", yTitle="Close Price", title="Commercial Bank Data Trend")
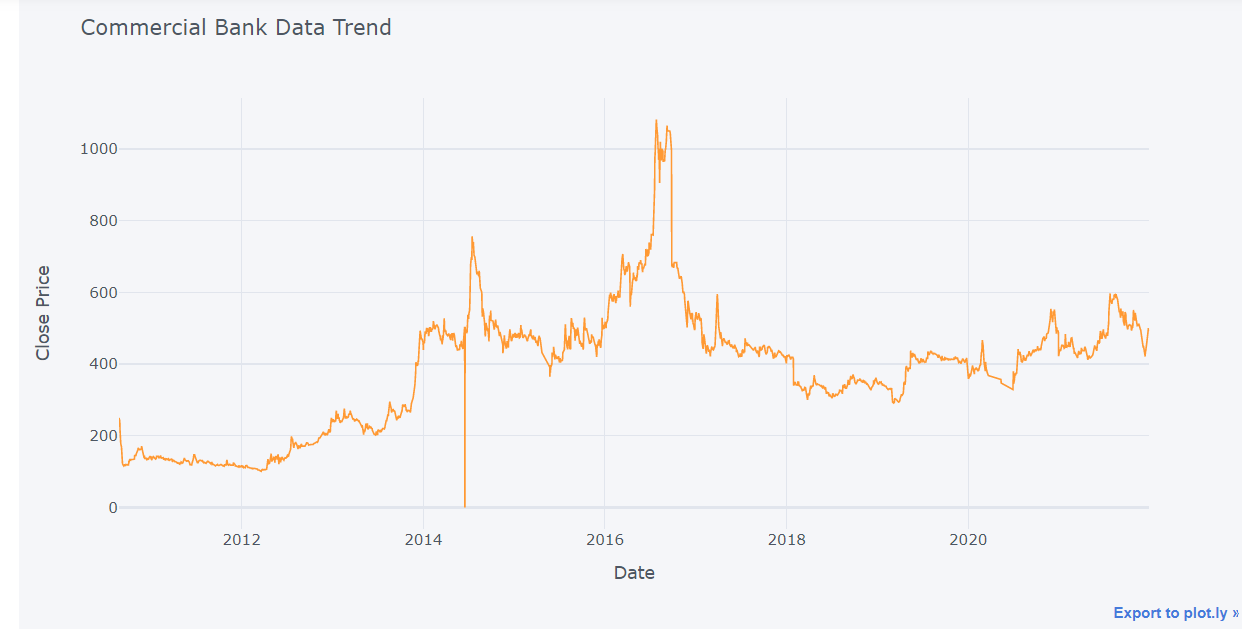
The graph shows that the initial closure price was around 270, and that it subsequently declined before gradually rising to its ideal level in July 2020, which was around 1200. Throughout the remaining time frame, there are frequent changes in closing price.
Next Price
To obtain the next price we shift close price one step back. Because tomorrow closed price is next price for today. And in next step we drop the missing values.
commerce['Next Price'] = commerce.shift(-1)['Close Price']
commerce= commerce.dropna()
Rename Columns
We changed the column names of the provided dataset because some of the original data’s columns weren’t initialized in the typical order; this made various manipulation chores easier.
commerce.rename(columns = {'S.N.':'SN','Total Transactions':'TTrans', 'Total Traded Shares':'TTS',
'Total Traded Amount':'TTA','Close Price':'ClosePrice','Next Price':'NextPrice',
'Max. Price':'MaxPrice','Min. Price':'MinPrice'}, inplace = True)
Prepared Feature
Here we take Closeprice and Date as a features and NextPrice and Date as outfeature.
features = ['ClosePrice',"Date"]
outFeature = ['NextPrice',"Date"]
Here we assign variable X and Y to the features and outFeasture variable.
# take close price as feature and next price as out feature
X, Y = commerce[features], commerce[outFeature]
X.set_index("Date", inplace=True)
Y.set_index("Date", inplace=True)
Normalize Data
Here, minmax normalization is used. To alter our data on the same scale, data standardization is increasingly necessary. Data normalization is therefore a crucial stage in the process of converting all data to the same measuring unit.
#Normalize data using standard scalar.
ss = StandardScaler()
X["ClosePrice"] = ss.fit_transform(X)
Y["NextPrice"] = ss.fit_transform(Y)
Train Test Split
Data will be randomly split using train test split of sklearn, losing the sequence. As a result, we created scratch sets for our train and test datasets. We divided the data as follows: we used 80% of the data for the train set, 10% for the validation set, and the final 10% for the test set.
def train_test_split(x,y,train_size):
n = int(len(x)*train_size)
trainx = x[:n]
testx = x[n:]
trainy=y[:n]
testy=y[n:]
return trainx,testx,trainy,testy
#Split train, validation, test set from X,Y to 80%, 10%, 10%
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.9)
X_train.shape,X_test.shape,X.shape
((2313, 1), (258, 1), (2571, 1))
In the code below we build the GRU model using time_step 5 using 20 input layer similarly 20 hidden layer we used Adam optimizer as optimization function. Mean square error as loss function
#Build the model using GRU
time_step = 5
model = Sequential()
model.add(GRU(20,input_shape=(time_step,1),return_sequences=True ))
model.add(GRU(20))
model.add(Dropout(0.3))
model.add(Dense(20))
model.compile(optimizer='adam',loss = 'mse')
We fit the model using x_train, Y_train, epochs, batch_size. Finally we obtain loss 0.0341.
#Fit model with history to check for overfitting
history = model.fit(X_train,Y_train,epochs=1,batch_size = 5,shuffle=False, verbose = 2)
463/463 - 1s - loss: 0.0341 - 1s/epoch - 3ms/step
Model prediction is done in the following block of code.
predictions = model.predict(X_test)
predictions = ss.inverse_transform(predictions)
#print(predictions)
9/9 [==============================] - 0s 2ms/step
Y_test_ss = ss.inverse_transform(Y_test)
rmse=np.sqrt(np.mean(((predictions- Y_test_ss)**2)))
print(rmse)
12.703591477147471
We obtain root mean squared error 12.703. We always prefer lower error value.


Comments